성능 개선을 하는 도중 인덱스 하나만 설정을 해도 성능이 엄청 향상되는 것을 경험했습니다.
그래서 인덱스가 도대체 무엇이길래 이렇게 성능에 큰 영향을 주는지 , 더 자세히 공부하고 싶어서 이 글을 작성하게 되었습니다
그럼 고고띠!

인덱스란 무엇인가요?
인덱스를 처음 접하면 " 그냥 빠르게 찾아주는 거 아닌가? " 하고 넘어가기 쉽습니다.
저도 그랬습니다. 그런데 부하테스트를 하면서 직접 설계해보니, 인덱스의 종류가 어떻게 동작하는지 제대로 이해하지 못하면 잘못된 인덱스를 달거나 오히려 성능이 나빠지는 상황이 생깁니다.
그래서 이번 글에서는 제가 공부하면서 정리한 인덱스의 종류와 각각의 동작 방식을 적어보겠습니다.
인덱스는 책의 목차와 같습니다. 책에서 특정 내용을 찾을 때 처음부터 한 장씩 넘기지 않고 목차에서 페이지를 찾아 바로 펼치는 것처럼 , 데이터베이스도 인덱스가 있으면 전체 테이블을 스캔하지 않고 원하는 데이터로 바로 접근할 수 있습니다.
다만 인덱스는 공짜가 아닙니다. 인덱스는 별도의 자료구조로 저장되기 때문에 디스크 공간을 차지하고 , INSERT, UPDATE, DELETE 시마다 인덱스도 함께 갱신해야 합니다. 그렇기 때문에 무조건 많이 다는 것이 아니라 쿼리 패턴에 맞는 것만 정확하게 설계하는 것이 중요합니다
먼저 이진 트리에 대해 알아보자
B-Tree 를 공부하기 앞서 먼저 이진 트리에 대해서 알아보겠습니다
왜냐하면 B-Tree 는 이진트리의 확장된 형태이기 때문입니다

만약 5번을 찾아간다 가정을 할 때
순차적으로 찾아가면
1 → 2 → 3 → 4 → 5
총 5번이 걸립니다
하지만 그림과 같이 이진트리로 인덱스를 관리하는 경우라면?
4 → 6 → 5
총 3번의 탐색만으로 5를 찾아갈 수 있습니다
이렇게 인덱스의 조회 성능을 이진트리를 사용하면 상당히 개선할 수 있습니다.
하지만 이진트리는 단점이 있습니다.
- 트리가 한쪽으로 경사질 수 있다
- 이진트리는 자식을 2개만 가질 수 있기 때문에...
저장하려는 키가 많아지면 트리의 깊이가 깊어지고 , 탐색해야 하는 수가 많아진다
결국 이진트리 인덱스를 사용해 봤자 순차 인덱스를 사용한 것처럼 최악의 경우 O(n) 번 탐색을 해야 합니다
B-Tree의 탄생
이러한 단점 때문에 B-Tree 가 탄생 하게 되었습니다.
B-Tree는 탄생했을 때부터 , 즉 애초부터 대량의 인덱스를 관리하기 위해 만들어진 자료구조입니다
특징
- 항상 Balance 유지
Balanced - Tree의 약자로 이름에서 보는 것과 같이 항상 Balance를 유지하고 있기 때문에 경사가 지지 않습니다 - 한 노드에 여러 개의 키를 저장 가능 (K개)
- 2개 이상의 자식을 가질 수 있다 (K+1개)
- 키가 항상 정렬되어 저장된다

그림에서 보는 것과 같이 하나의 노드에 하나가 아니라 2개 이상의 키가 저장되어 있다 (3,6) , (12, 15)..
그에 따라서 자식의 개수 또한 증가하게 된다
예를 들어 3과 6이 저장된 노드가 있다. 그러면 그 값의 기준으로 구간이 나뉘어
- 3 보다 작은 값들
- 3과 6 사이 값들
- 6보다 큰 값들
이렇게 3개의 범위 가 생긴다
즉 부모의 노드 속 키 값이 N개면 자식은 N+1 개 생긴다
여기서 가장 하위의 노드를 리프 노드라고 부르고 가장 상위의 노드를 루트 노드라고 부릅니다
그리고 리프와 루트 노드 사이의 노드들을 브랜치 노드라고 부릅니다
그럼 이번에도 10번의 노드를 찾아가 보겠습니다
9 → 12 → 10
단 3번 만에 찾아갈 수 있습니다 이진트리와 똑같지만 B-Tree는 경사가 지지 않기 때문에
그 어떤 상황에도 최악의 경우에도 이진트리보다 더 빠릅니다
단점
하지만 B-Tree 도 단점이 있습니다

방금처럼 10번 이렇게 단일 검색이 아니라 10번부터 13번 ID를 가지는 범위검색을 하는 경우
루트노드에서 시작을 해서 9 → 12번 레코드는 바로 찾아갈 수 있고 12번에서 인접해 있는 노드인 10 번과 11번 까지 찾아 갈 수 있습니다.
이제 13번을 찾아가야 하는데 13번 위치기 지금 위치와는 다른 노드에 있기 때문에 바로 접근하지는 못하고
루트 노드에서 다시 9 → 12 → 13 순으로 탐색을 해야 합니다
즉 범위 검색에 있어서 큰 장점을 발휘하기 어렵습니다
B+ Tree의 탄생
- 기존의 B-TREE의 단점을 보안한 B-Tree의 종류
- 리프 노드에 모든 키가 존재
- 키와 연결된 레코드에 대한 주소를 리프 노드에서만 가진다
- 가장 큰 특징은 같은 높이의 노드들은 서로 연결되어 있다

그럼 B+ TREE를 이용해 7번 8번 9번 범위 검색을 진행해 보겠습니다
루트노드를 통해 7 → 9 → 7,8번까지 다 찾아갈 수 있습니다
이제 다른 노드에 있는 9번 레코드를 찾아가야 하는데 기존의 B-Tree 였다면 9번이 다른 노드에 있기 때문에 다시 루트에서 찾아 가야 합니다 하지만 B+Tree 는 같은 높이끼리는 이어져있기 때문에 9번으로 바로 접근할 수 있습니다
이렇게 B+Tree 는 범위 검색에 있어서도 상당히 효율적인 모습을 보여주고 있어서, 현대 DBMS 들 MySQL , ORACLE 은 이 B+Tree 자료 구조를 사용합니다
B+Tree의 삽입 연산 (k=3)
일단 하나의 노드에 저장될 수 있는 키의 수를 3개로 가정하겠습니다
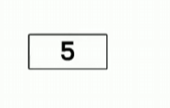
이렇게 5번이 저장된 상태에서 7번 아이디를 가진 레코드가 삽입되려고 합니다.

이진트리 삽입과 동일하게 7은 5보다 크기 때문에 5의 오른쪽으로 삽입됩니다
이제 다음으로는 6번 레코드가 삽입되려고 합니다

이번경우에도 마찬가지로 6은 5보다 크고 7보다 작기 때문에 사이로 들어가게 됩니다
이제 이 상태에서 4번 레코드가 삽입되려고 합니다 4 같은 경우는 5보다 작기 때문에 5의 왼쪽으로 삽입될 것 같은데

이렇게 되면 하나의 노드가 가질 수 있는 최대 키의 개수인 3을 초과했기 때문에
분할을 해줘야 합니다 하지만 리프 노드를 쪼개는 경우에는 단순히 반으로 나누면 되는 게 아니라 가운데 위치한 노드 하나를 상위 노드로 복제를 시킨 후에 나누어진 두 개의 노드를 연결을 해줘야 합니다
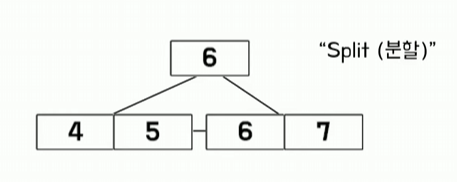
가운데 위치한 두 개의 노드 5와 6중에서 6번을 상위로 복재시킨 다음에 두 개로 쪼개서 상위 노드와 연결해 주겠습니다
이렇게 최대 키의 개수를 2개로 쪼개는 과정을 Split이라고 부릅니다
이 Split 과정을 통해서 B-Tree는 항상 균형을 유지하게 됩니다
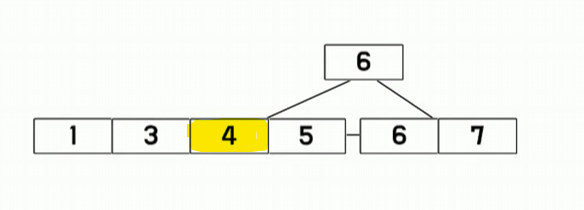
똑같이 이렇게 삽입이 이뤄지면

Split을 통해 쪼개지게 됩니다


또다시 삽입이 이뤄지면서 최대 노드의 크기 이상의 값이 저장되게 되면
Split을 통해 또 쪼개지게 됩니다
정리
- B+ 트리는 대량의 인덱스를 관리하기 위해 고안된 자료구조
- B+ 트리는 항상 군형을 유지하며, 상당히 빠른 조회 속도를 보장한다
- B+ 트리 인덱스는 키 순서로 정렬되어 있어서 직전/직후 키를 빠르게 찾을 수 있으며 순차 탐색에 유리하다
- B+ 트리는 각 레벨의 노드들이 연결되어 있는 B+ 트리로 범위 검색을 매우 효율적으로 처리 가능
참고 자료
https://www.youtube.com/watch?v=MuZ-Mx0N-dA
'🖥️ 컴퓨터 공부' 카테고리의 다른 글
| 나머지 API 들 부하테스트 (0) | 2026.04.25 |
|---|---|
| 내 프로젝트 Index 분석하기 (0) | 2026.04.25 |
| MySql- Show Index , Explain필드 분석 (0) | 2026.04.24 |
| 인덱스의 종류 (0) | 2026.04.24 |