다시 성능 최적화를 진행해 보겠습니다...
Redis 병목을 잡고 나서 이번엔 DB 쿼리를 하나씩 들여다보기 시작했습니다. 그러다 체크리스트 삭제 쿼리에서 이상한 부분을 발견했습니다.
DELETE FROM member_document_check
WHERE member_id = ?
AND document_id IN (
SELECT document_id FROM document WHERE announce_id = ?
)
얼핏 보면 멀쩡해 보입니다. 그런데 member_document_check 테이블에는 announce_id 컬럼이 없습니다. 삭제 대상을 특정하기 위해 반드시 document 테이블을 서브쿼리로 거쳐야 하는 구조였습니다.
단건 요청이라면 문제가 없습니다. 하지만 MySQL은 DELETE 실행 시 서브쿼리에 포함된 테이블까지 락 범위가 확장됩니다.
즉, member_document_check만 건드리는 쿼리인데 document 테이블에도 락이 걸리는 것입니다. 동시 요청이 몰리는 부하테스트 환경에서는 이 넓은 락 범위가 곧바로 경합으로 이어졌습니다.
해결 방법은 생각보다 단순했습니다. 쿼리를 두 단계로 명시적으로 분리하면 됩니다.
@Override
public void deleteChecklist(Long memberId, Long announceId) {
// 1단계: document_id 목록 조회 (SELECT만, 락 없음)
List<Long> documentIds = queryFactory
.select(document.id)
.from(document)
.where(document.announce.id.eq(announceId))
.fetch();
if (documentIds.isEmpty()) return;
// 2단계: 조회한 id로 정확한 row만 삭제
queryFactory
.delete(memberDocumentCheck)
.where(
memberDocumentCheck.member.id.eq(memberId),
memberDocumentCheck.document.id.in(documentIds)
)
.execute();
}
1단계는 SELECT이기 때문에 락이 발생하지 않고, 2단계 DELETE는 member_document_check 안에서 정확한 row에만 락을 겁니다. 쿼리가 1번에서 2번으로 늘어났지만 동시 요청이 몰려도 각 요청이 서로의 row를 건드리지 않기 때문에 경합 자체가 사라졌습니다.
이때 처음으로 깨달았습니다. 쿼리 수를 줄이는 것이 항상 정답은 아닙니다. 동시성 환경에서는 얼마나 좁은 범위에 락을 거느냐가 훨씬 중요합니다.
인덱스도 함께 추가했습니다. 1단계 SELECT에서 document.announce_id에 인덱스가 없으면 풀스캔이 발생하고, 2단계 DELETE에서 (member_id, document_id) 복합 인덱스가 없으면 삭제 대상을 찾는 데 불필요한 스캔이 발생합니다.
CREATE INDEX idx_doc_announce ON document (announce_id);
CREATE INDEX idx_mdc_member_doc ON member_document_check (member_id, document_id);
/home API - Thread.sleep(50).. 개선
/home API는 공고 목록을 Redis에 캐싱해두는 Look-Aside 구조를 사용하고 있었습니다.
TTL이 만료되는 순간 수백 개의 요청이 동시에 캐시 미스를 경험하고 한꺼번에 DB로 쏟아지는 Thundering Herd 문제를 막기 위해 분산 락도 도입되어 있었습니다.
여기까지는 좋은 설계입니다. 문제는 락을 얻지 못한 요청들을 처리하는 방식에 있었습니다.
// 락 못 얻은 요청의 기존 처리
try {
Thread.sleep(50); // 50ms 스레드 블로킹
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
List<String> retried = stringRedisTemplate.opsForList().range(key, 0, -1);
락을 얻지 못하면 50ms 대기 후 캐시를 재조회하는 방식이었습니다. 언뜻 보면 합리적으로 보입니다. 락을 얻은 요청이 캐시를 채울 때까지 잠깐 기다렸다가 캐시를 읽으면 DB 호출을 아낄 수 있기 때문입니다.
그런데 Thread.sleep()은 해당 스레드를 완전히 블로킹시킵니다. 동시 요청이 500개라면 락을 얻지 못한 499개의 스레드가 전부 50ms씩 잠들어버립니다. Tomcat 스레드 풀이 순식간에 고갈되고, 그 여파가 전체 응답 시간을 끌어올리는 구조였습니다.
해결은 단순합니다. 기다리지 말고 바로 DB에서 조회하면 됩니다.
// 락 획득 실패 → 대기 없이 즉시 DB 폴백
return dbFallback.get();TTL 만료 직후에는 락을 얻은 단 1개의 요청이 캐시를 채우고, 나머지 요청들은 DB에서 직접 조회합니다. 스레드를 블로킹하지 않기 때문에 Tomcat 스레드 풀이 고갈될 일이 없고, 캐시가 채워지는 순간부터 이후 요청들은 다시 캐시에서 빠르게 응답합니다.
또 다시.. 성능 테스트..


나름의 성능 튜닝을 계속하고 있지만 성능향상은 거의 보이지 않고 있습니다
이전과 비교를 해보면
| 이전 | 현재 | 개선 | |
| checklist 실패율 | 13.7% | 0.06% | |
| api_error_reate | 4.46% | 0.61% | |
| home p95 | 1785ms | 1757ms | 소폭 |
| checklist p95 | 1268ms | 1193ms | 소폭 |
또 또또또또 성능 튜닝..!!
배치가 한 번도 안 돌고 있었습니다
여러 차례 최적화를 진행했는데도 Redis 메모리가 계속 증가하고 있었습니다. 이상하다 싶어서 원인을 추적하다가 충격적인 사실을 발견했습니다.
배치가 단 한 번도 실행되지 않고 있었습니다.
원인은 허무하게도 @EnableScheduling 어노테이션 누락이었습니다. @Scheduled를 메서드에 붙여도 이 어노테이션이 없으면 스케줄러 자체가 동작하지 않습니다. 인기 공고 집계도, Redis 만료 키 정리도 전부 실행되지 않은 채로 테스트가 진행되고 있었던 것입니다.
@SpringBootApplication
@EnableScheduling // ← 이게 없었습니다
public class Application { ... }
어노테이션 하나를 추가하고 나서 배치가 정상 동작하기 시작했고, 다시 성능 최적화를 진행하였습니다.
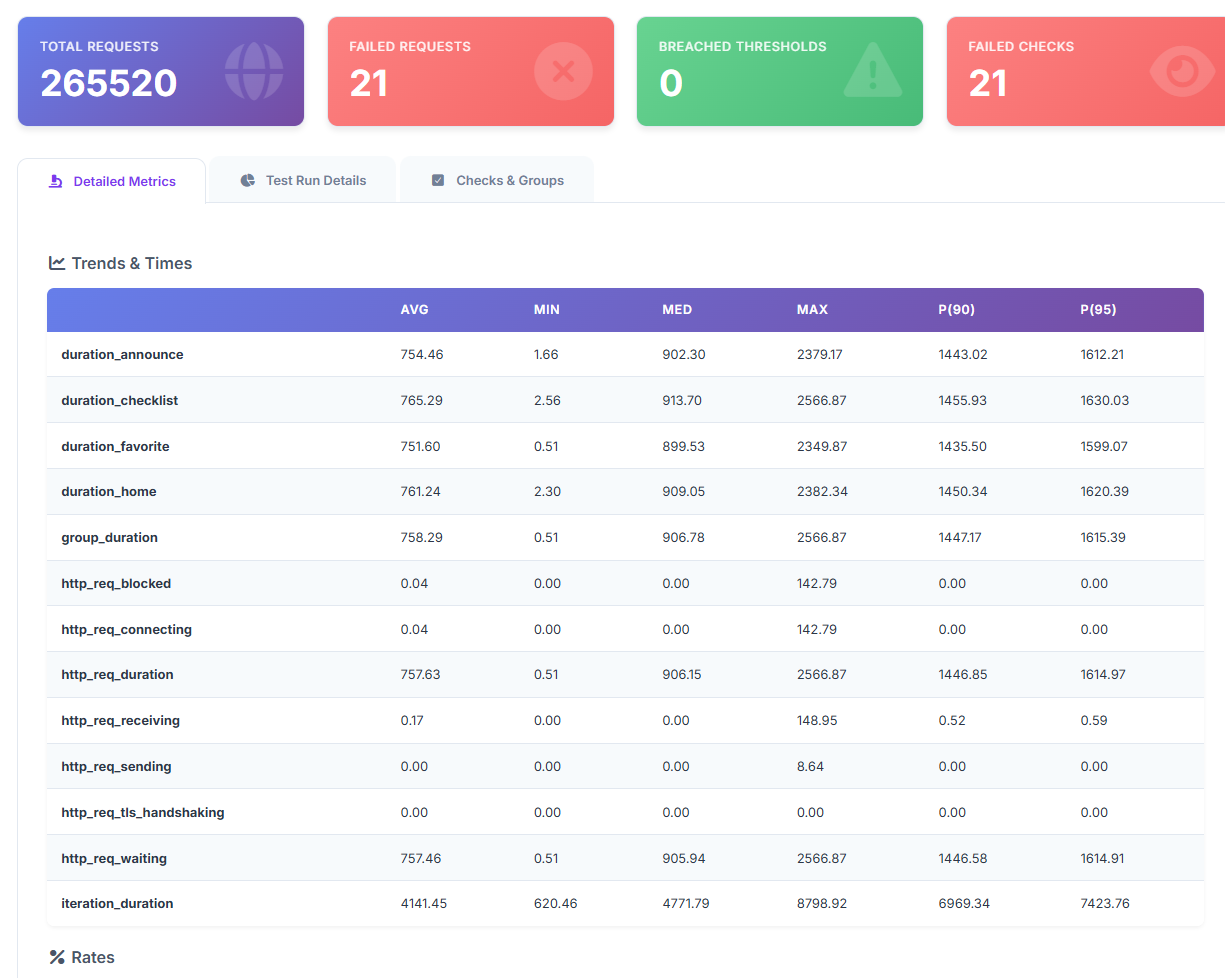

결과를 보면 Redis 메모리도 드디어 안정적으로 유지되기 시작했습니다.
그리고 재밌는 변화가 하나 더 생겼습니다.
이전까지는 4개 API 중 /home만 유독 응답 시간이 튀었는데, 배치가 돌기 시작하면서 4개 API의 P95가 거의 동일한 수준으로 균등해진 것입니다.
- home: 1620ms
- favorite: 1599ms
- announce: 1612ms
- checklist: 1630ms
수치 자체는 여전히 목표에 한참 못 미쳤지만, /home 병목이 해결되었다는 신호였습니다. 전체적으로 높은 이유는 CPU 때문이었습니다. 부하테스트 스크립트가 4개의 API를 동시에 호출하고 있었기 때문에, 목표 1,000 TPS 기준으로 서버 입장에서는 사실상 3,000~4,000 TPS에 가까운 환경이었습니다.
그래서 다음 단계로 각 API를 개별적으로 분리해서 테스트해 보기로 했습니다.

'🖥️ 컴퓨터 공부 > 부하테스트 & 성능최적화' 카테고리의 다른 글
| 해커톤 성능 최적화 — 전체 정리 (0) | 2026.04.27 |
|---|---|
| 해커톤 성능 최적화 -4 (1) | 2026.04.24 |
| 해커톤 성능 최적화 -2 (0) | 2026.04.24 |
| 해커톤 성능 최적화 - 1 (0) | 2026.04.24 |
| k6 와 그라파나로 성능최적화 도전 (0) | 2026.04.24 |